

If you don’t know it, stable diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
You can try it online on various websites and discord servers, but some days ago I stumbled upon this repository and I decided that I wanted to run stable diffusion on my own computer, both to try it with more freedom and to test my GPU, since I don’t know really how much computing power these kind of models need.
I will gloss over the fact that yesterday morning the installation readme made me install conda, python, wsl, ubuntu, nvidia GPU drivers and docker, then I went out while pulling the 17 gb docker image and came back finding an updated readme with a one-click exe installer!
So now it’s very simple, you just need to download the zip file and (very important) extract it directly into C or in the shortest path you can, because otherwise windows will complain about file path lenght and abort the installation.
After extracting the folder, double click the Start Stable Diffusion UI.cmd file and then go out for a walk, because it will take a lot of time. The total space occupied after the installation is around 18 GB!
The model itself, in the pythorch’s .ckpt format is more than 4 GB:

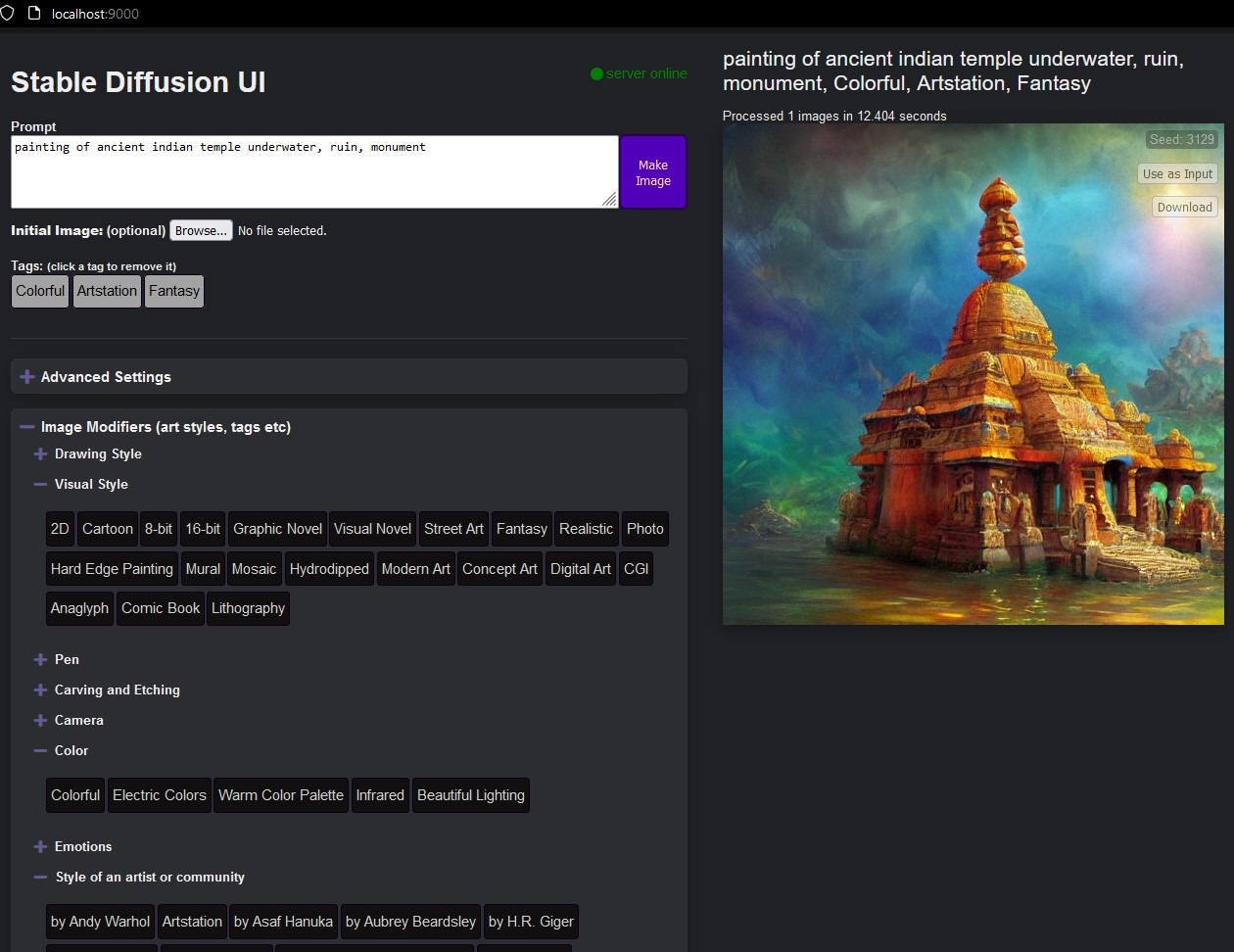
After the installation is complete, run the cmd file again and go to localhost:9000 to open the UI where you can insert the text prompt, image modifiers and other settings. You can have a full view of the ui here.
For my first test, I put this:
In the middle of a swamp, A black dragon is resting atop a tall white marble pillar. The sky is cloudy.
After approximately one minute on my geforce 1060 6 Gb, this was the result:

The image is 512×512. You can increase it up to 1024×1024 in the settings, but any resolution higher than 512 gave me a VRAM out of memory error 🙁
As you can see from the result, the dragon is there, the pillar is there, the sky is cloudy and.. is that a swamp in the back? Let’s try to use the same seed and apply a modifier!








{kind=link}